Saturday, 6. August 2016
Aug 06
TL;DR available at the bottom of the post.
“A React Native App is a Real Mobile App”
With React Native, you don’t build a “mobile web app”, an “HTML5 app”, or a “hybrid app”. You build a real mobile app that’s indistinguishable from an app built using Objective-C or Java. React Native uses the same fundamental UI building blocks as regular iOS and Android apps. You just put those building blocks together using JavaScript and React. [project site]
That doesn’t sound too bad, but why do we have to do it in JavaScript?
Well, this article shows that we don’t have to.
The nightwatch app
Consider you are working for some kind of Nightwatch and it’s getting dark and your watch is about to begin.
The nice people of your order gave you a phone and a new app. At the beginning of the night it downloads a list with locations that you have to check. Every location can be marked as OK or you can blow a virtual horn to trigger an alarm. The app also allows you to append an photo of the situation on the ground.
Since many of the locations that you will visit are far away from good internet connection the app stores everything locally on your phone. Once in a while it will sync with the nightwatch central.
So this could look a bit like this:

So now after embaressing myself and┬Āshowing my design skills, let’s jump into the technical stuff.
Developing with F# in VS Code
The app was developed with F# in Visual Studio Code┬Ā(with ionide and react native plugins). This development environment┬Āruns on all platforms, so you can use┬ĀWindows, Linux or your Mac.

As you can see we have a React Native app with┬Āautomatic loading of compiled F# code.
The big difference to using JavaScript is that everything is statically typed – even the access to the JavaScript APIs. This gives you nice autocomplete features and depending on the concrete bindings you can even get documentation in the editor:

Krzysztof Cie┼ølak did really amazing work with the Ionide – this tooling works pretty well. Take a look at his blog to find out more about the awesomeness that he brings to the ecosystem. He also played an important part in┬Āgetting React Native to work with F#.
Introducing Fable
Fable is the most important technology behind all of this. It was designed by Alfonso Garcia-Caro┬Āas a F# to JavaScript compiler and can do real magic in the browser. Take the time and watch the 10min intro. I can’t stress enough how well this open source project is managed. It’s┬Āa real pleasure to be part of it now.
In our case it bridges React Native APIs into F# and also compiles the F# code back to JavaScript whenever we save a file. The React Native framework is listening for the changes in the JavaScript files and swaps the code in the device simulator. There is a lot going on behind the scenes, but it’s already working surprisingly well.
Using┬ĀJavaScript APIs
Since most of the React Native APIs are developed in JavaScript it’s important to bring these APIs over to F#. This is done as┬Āa community effort and the Fable project creates typed JavaScript bindings for many┬Āmajor JavaScript frameworks. This effort is comparable to DefinitelyTyped in the TypeScript world. There is even a tool that can help to convert TypeScript bindings to Fable bindings.
In our case the fable-import-react-native┬Āis the most important package. It provides typed bindings to most of the React Native APIs.
This snippet creates a View component┬Āin React Native and puts two buttons inside it.
Using F#
One nice benefit of this model is that we can use┬Āordinary, statically typed F# code for our app. In the demo project you can find a small F# domain model:
If you are interested in learning the language then I recommend to look at website of the F# software foundation. For domain driven design in F#┬Āyou can find excellent articles on┬Āa site called “F# for fun and profit“.
Access to native components
React Native allows you to access native phone components like the camera. Most of these APIs are written in a mix of Java/ObjectiveC and JavaScript. Given the Fable bindings are already present it’s super easy to access the same APIs from F#. In the following sample we access a nice ImagePicker via the fable-import-react-native-image-picker bindings:
This ImagePicker is distributed via a separate npm package, but it’s API feels like the rest of the React Native functions. We can provide some properties and a callback – and everything is statically typed so that we have autocompletion in VS Code.
Data storage
For most apps you want to have some local storage in order to cache information. React Native provides a basic abstraction called AsyncStorage that works on Android and iOS. With the help of a package called fable-react-native-simple-store we can use it from F#:
As you can see all function in this storage model are asynchronous and with the help of the async computation expressions┬Āthey become really easy to use in F#.
Web access
Another advantage of┬ĀReact Native is the huge ecosystem you see on npm.┬ĀIn our app we want to retrieve a list with locations that we need to check. This list is just a bit of JSON on a http resource. With the help of a very popular JavaScript package called fetch and the corresponding┬Āfetch-bindings┬Ā(written by Dave Thomas)┬Āwe can write something like this:
So we see the same async model here and everything fits nicely together.
Project status
The project with the working title┬Ā“Fable |> React Native” is currently considered “highly experimental”. APIs and JavaScript bindings are not complete and likely to break multiple times.
In general the Fable project is shaping things up for a v1.0 release. So sharing experiences, comments and bug reports with the Fable compiler and APIs is appreciated.
Debugging of the react native apps is currently only working in┬Āthe generated JavaScript.┬ĀWith┬Āthe next release of the VS Code react native extension┬Āwe will probably be able to set breakpoints directly in the┬ĀF# source.
That said, it already feels very very productive and if you are interested in this kind of mobile development then check out the sample project and follow┬Āhow it develops over time. There is even a similar approach that allows you to use F# on fuse,┬Āso I think we will probably see a lot of choice in the future.
TL;DR for F# devs
With this model you can start to develop Android and iOS apps on the react native model┬Āwhile still keeping most of the type safety and tooling. Using fable┬Āgives you access to a huge ecosystem with JavaScript libraries and frameworks. Check out the sample project┬Āand follow the instructions in the Readme.
TL;DR for JavaScript devs
If you like creating apps with the┬ĀReact Native model, but it always felt a bit hard to maintain JavaScript, then this might be interesting for you. With this approach you can apply all your knowledge and use it from a excellent type safe language with amazing autocompleting tooling.
With one or two tricks you can even reuse many┬Āof the npm libraries that you know and love. Check out the sample project┬Āand follow the instructions in the Readme.
TL;DR for TypeScript devs
You have already left the path of plain JavaScript. Maybe you are ready to leave it a bit further┬Āand to investigate different languages like Elm or PureScript. If this is you then┬Ācheck out the sample project┬Āand follow the instructions in the Readme. It shows you how a language like F# can help you to work with JavaScript APIs.
TL;DR for C# devs
Sorry, nothing to see here.
Tags:
F#,
reacr-native,
react,
react-native
Thursday, 31. March 2016
Mar 31
The problem
Last week┬Āmost of us┬Āheard that latest npm drama where “one developer broke Node, Babel and thousands of projects in 11 lines of JavaScript“. The reason for this huge impact was that┬Āall of these projects (even infrastructure critical projects like Node) relied on the fact that packages are available on npm until the end of time. But users are allowed to delete packages permanently. Oups!
In .NET/mono land things are slightly better. Users can’t delete packages from nuget.org, they are only allowed to “unlist”. Unlisted packages won’t be suggested┬Āfor new installations, but are still available on the server so that builds won’t break. In most cases this┬Āis a good thing for users, but even on nuget.org packages can be removed permanently┬Āand this already affected some projects.
If you are using TeamCity as CI server and also as NuGet feed then things are looking bad as well. TeamCity’s cleanup task removes all artifacts from your projects – including NuGet packages. So if you forget to pin a build that generated an important NuGet package then TeamCity’s cleanup will eventually delete that package. This hit us a couple of times now and ironically also right now. ¤Öü
Paket caches to the rescue
For Paket v3 (currently in alpha) we implemented a solution for this problem. With this version we can configure additional caches┬Āwhich will automatically be used to store all external dependencies in a safe and controlled location.
This feature would have protected us, but in our case the damage was already done. The package was already “cleaned” from the TeamCity NuGet feed and most of our builds broke. So in order to fix this┬Āwe did the following:
Et voil├Ā: all builds on all TeamCity agents and developer machines became green again.

Monday, 21. March 2016
Mar 21
A couple of days ago I tried to fix a bug in the .NET/mono dependency manager “Paket“. The bug was a really strange edge case in Paket’s resolver algorithm that resulted in a false positive conflict (an overview about the algorithm can be found here).
In other words: Paket reported a version conflict where it should have reported a valid package resolution.
After some investigation I found that the bug was in some optimization code that tries to cut parts of the search tree. When I disabled that part, the resolver found a valid resolution, but was significantly slower. So after some further testing I came up with a fix that was fast and solved the issue.
But why didnŌĆÖt we find that edge case before? And most importantly: do we have other bugs in the resolver?
Isaac Abraham suggested to investigate the resolver optimizations further and proposed to use property based testing for this (see Scott Wlaschin’s blog for amazing introduction material).
Problem formulation
In this post I want to evaluate if Paket’s package resolver works correct. Let’s start by clarifying some terms.
- A “package” consists of a name, a version and a (possibly empty) list of dependencies. In this post we are only talking about meta data. The package contents are irrelevant.
- A “dependency” is always referencing another package name and defines a version requirement (e.g. >= 2.0 or < 4.1).
- The “package graph” is a list of packages and acts as a stub for a possible configuration of a package feed like nuget.org. It’s basically a collection of the meta data of all published packages.
- A “resolver puzzle” consists of a package graph and a list of dependencies. In other words it defines a possible configuration of the package feed and a specific list of package requirements (basically what you would define in paket.dependencies).
- A “resolution” is a list of packages that “solves” the resolver puzzle. This means all package requirements are satisfied┬Āand┬Āwe don’t have more than one package for a every package name.
Our goal is to show that Paket’s resolver is returning a version conflict if and only if we can not find a package resolution via a brute-force algorithm. We do not compare resolutions, we just want to know if the optimization is missing some valid resolutions.
Generating test data
Property based testing is a stochastical test approach. The test framework (in this case we use FsCheck) generates lots of test cases with random data and tries to automatically falsify a given assumption about the algorithm.┬Ā
Usually FsCheck will just generate random, uniformly distributed┬Ādata for whatever data type it sees. This is a very good default, but in our case this would result in 99% package graphs that have no resolution.
In order to create more sensible data and increasing the likelihood of finding real bugs we need to write our own generator functions.
LetŌĆÖs consider a very small example and think about package names. If we would use the standard FsCheck data generator then it would generate completely random names including empty string, null and names that contain very special characters. While this is┬Āgreat for testing the validation part of Paket, we donŌĆÖt really need this here. We just generate some valid package names:
As you can see we just generate non-negative integers and create the package name by prefix a “P”. Similarly we can create random but valid version numbers like that:
Here we just map a triplet of non-negative integers to a version of form major.minor.patch.
Now it’s easy to┬Āgenerate a list of packages with corresponding versions. Actually FsCheck can automatically generate a list of PackageName and Version pairs, but since it’s completely random it would generate a list where most packages have only one or two versions. The following custom generator creates a list of different versions for every package and flattens the result. This has a much bigger chance of creating interesting cases:
With a small helper function that creates random version requirements we can create a full package graph:
The last step is to create some package requirements to that graph that we want to resolve. This is basically what you would write into your paket.dependencies file.
Testing against brute-force algorithm
The following defines a FsCheck property that calls Paket’s resolver with a random puzzle. If the resolver finds a resolution, then we verify that this resolution is correct. If it can’t find a resolution we use a brute-force algorithm to verify that the puzzle indeed has no valid resolution:
This is testing the real resolver against a very naïve brute-force implementation. The brute-force version was relatively easy to write and has no smart optimizations:
And this point I reverted the fix in the optimization code and started the test to see what happens. FsCheck needed about 3s to come up with a random example where a valid resolution exists but Paket’s resolver didn’t find it. That was an amazing moment. Unfortunately the example was HUGE and very complicated to understand.
Shrinking
Most property based testing frameworks have a second important feature called “shrinkers”. While generators create random test data, shrinkers are used to simplify counter-examples and have type ‘a -> seq<‘a>. Given a value (our counter-example), it produces a sequence of new examples that are “smaller” than the given value. These new values are tested if they still falsify the given property. If they do a new shrinking process will be started that tries to reduce the new example even further.
There are two easy ways to create a new “smaller” graph. The first optios is to select a package from the graph and remove one of it’s dependencies and second option is to remove a package completely. The following code shows this:
In a similar way we can shrink a puzzle:
After running the test again FsCheck reported:
The ouput shows that FsCheck generated a random puzzle with 104 packages and reduced it to a sample with only 3 packages and 2 package requirements. This made it pretty easy to analyze what was going on in the optimization part of the resolver. The sample was even smaller than the one that was reported from the wild.
With the fix reapplied I rerun the tests and FsCheck reported another error:
So now FsCheck discovered a new, previously unknown bug in Paket’s resolver. The sample shows 2 packages and one of the packages is requiring a non-existing package.
This is trivial case and the brute-force algorihm is instantly finding a solution. So what is wrong in Paket’s resolver?
Again the answer is hidden in some performance optimization and the fix can be found here.
But this was not the end – the property based test spotted yet another counter-example so I fixed that as well.
Conclusion
It took me a while to build up property based testing for this complex scenario. Most of the time was needed to build custom generators and shrinkers, but I was able to reproduce a bug from the wild and also found two new bugs. I think this is a big success.
Monday, 21. December 2015
Dec 21
[This post my second entry of the F# advent calendar 2015 series. You can also read the first post about “Using Async.Choice in Paket“]
Recently┬ĀI was asked to help with a website that was based on suave.io. The task was to transform the existing F# script based suave.io website to something that can be run in the enterprise infrastructure and also performs some background tasks like creating Excel reports recurringly.
Suave as a (windows) service
A lot of the suave.io samples work with simple .fsx script files. This approach is indeed simple and allows fast prototyping with the use of the REPL. Even more complex websites like fssnip.net┬Āare using this approach with great success (code here).┬ĀOne of the benefits of script based suave solutions is that they are often equipped with a FAKE build script that rebuilds the website automatically if someone changes a file. One prominent example┬Āis FsReveal:

But sometimes you want to have a “real Visual Studio project” with debugging support and your enterprise might want to install┬Āyour website as a Windows service. So the first step was to convert the F# script based approach into a project and adding TopShelf layer to make it runnable as Windows service. Thanks to a short blog post by Tomas Jansson this was super easy. It’s basically just installing TopShelf.FSharp via Paket┬Āand adding a single file with the config. Look into Tomas’s blog post to see the details.
After moving┬Āto the TopShelf model we still wanted to have automatic website rebuild whenever someone touched the source code. This little FAKE script makes this possible:
Running background jobs
The website already allowed to generate Excel reports by clicking somewhere in the UI. In addition to that we wanted to create the Excel reports recurringly in background jobs.┬ĀScott Hanselman has a blog post about “How to run Background Tasks in ASP.NET” and shows a couple of┬Āsolutions that while optimized for ASP.NET would probably work with suave.io as well. But in this case we wanted to have something that syncronizes with the IO of the website so we decided to use F#’s MailboxProcessor feature a.k.a. “agents”. (As always: Scott Wlaschin has a nice introduction to agents.)
As a small intro into background jobs we start with F# counter agent sample by Tomas Petricek:
This little snippet shows an agent that calculates averages of the messages that it receives. Now let’s add a background job that recurringly sends messages to the counter agent:
In order to use this we need a bit of ugly infrastructure code that we will hide in a library:
So let’s try this out in the F# interactive:

Since this works as expected we can use it in our website:
Since all the user triggered reporting will also go through this taskAgent we ensure that IO is synchronized.
Sample project
In https://github.com/forki/backgroundjobs you can find a sample project which does exactly the two points from above.

As you can see the website performs background jobs and is rebuilding/restarting automatically when a source code file is saved.
Tags:
F#,
fsadvent,
fsharp
Monday, 30. November 2015
Nov 30
[This post is part of the F# advent calendar 2015 series.]
Prologue: What is Paket?
Paket┬Āis a dependency manager for .NET with support for NuGet packages and GitHub repositories. It enables precise and predictable control over what packages the projects within your application reference.┬ĀIf you want to learn how to use Paket then read the “Getting started” tutorial and take a look at the FAQs.
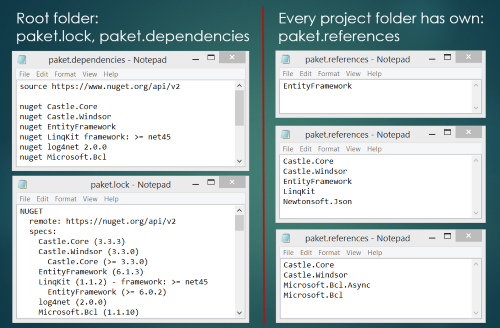
Async computations in F#
Asynchronous Workflows are a very old F# feature (they already shipped in 2007) and┬Āthey are┬Āused in many places in Paket. In this article I want to highlight one of the nice applications that F#’s async model allows you.
Many readers are probably familiar with C#’s async and await keywords (IIRC released with C# in 2012), but F#’s async feature works a little different.┬ĀYou can read more about some of “Asynchronous gotchas in C#” in Tomas Petricek’s excellent blog post. Most of these gotchas come from the fact that C# is starting all async tasks automatically while F# wraps the logic in data and allows you to run it explicitly. For a really good introduction to asynchronous programming with F# I can recommend Scott Wlaschin’s blog post.
The issue: retrieving version numbers from NuGet feeds
Paket’s package resolution algorithm (if you are interested in algorithms then read more) needs to know which versions are avalaible for a given package. Usually users specify more than one NuGet feed and different NuGet feeds support different protocols. The following code shows how older Paket versions retrieved all version numbers for a given package across all configured NuGet feeds:
As you can see getAllVersions tries 4 different NuGet protocols per source and returns the first result that is not None. Every getVersionsViaProtocol call performs async web request. In GetAllVersions we run this function for every NuGet source in parallel and combine the results. This code is very similar to the “async web downloader” sample in Scott Wlaschin’s async blog post┬Āand basically the “hello world” of asynchronous programming.┬Ā
Code cleanup
The getAllVersions is deeply nested and it’s hard to understand what’s going on. With the help of List.tryPick we can rewrite the code as:
List.tryPick returns the first result that is not None. So instead of nesting multiple match and let! expressions we use a higher-order-function to encapsulate the same pattern.
Introducing Async.Choice
After using this code for a while in Paket we noticed that different NuGet server implementations each implement a different subset of the 4 protocols and differ very much in the response times. So there was no order of the protocols that would work good for all server implementations. But what if we could query all 4 protocols in parallel and just take the fastest response?
The change is relatively easy and we can rewrite the┬ĀGetAllVersions┬Āas:Instead of running the web requests synchronously and in order we run the four web request per NuGet feed in parallel and take the first response that is not None.
Implementation of Async.Choice
Unfortunately Async.Choice is not part of the standard FSharp.Core library and it turns out it is not easy to implement. There are many different implementations┬Āfloating around on the internet. The one we use in Paket is by Eirik Tsarpalis and taken from fssnip. One of the advantages of this version is that the automatic cancellation of tasks┬Āworks nicely. Since we are running lots and lots of web requests in parallel and always take the first response we want to cancel all the other pending web requests. Otherwise we would basically DDOS the feeds with useless requests (and yes that happened to us ;-)). Since Async.Choice is very useful we sent a pull request to the Visual F# project and hope that one day it will be in the box.┬Ā
Epilogue
Treating computations as data has even more advantages. The m-brace project created a new version of computation workflows called “cloud”:
cloud┬Āis a computation workflow builder and allows you to run your computations in the cloud. In┬Ācontrast to async we don’t only control when something gets executed but also where. They even have a Cloud.Choice, which allows you to run tasks asynchronous in the cloud and take the first succeeding result.
Btw:┬Āasync and cloud aren’t language keywords like C#’s async and await, but implemented as normal F# code in libraries. If you want to┬Ādefine your own computation expression builders, then the MSDN docs are a good starting point.
Tags:
async,
F#,
fsadvent,
fsharp
Wednesday, 14. October 2015
Oct 14
As many readers already know I’m maintaing the open source projects FAKE and Paket. These projects are used in many companies and open source projects to make continuous integration work on .NET and mono.
In this article series I want to highlight some of the more┬Āunsual┬Āuse cases. Today I want to start and highlight the first 6 amazing┬Āprojects.
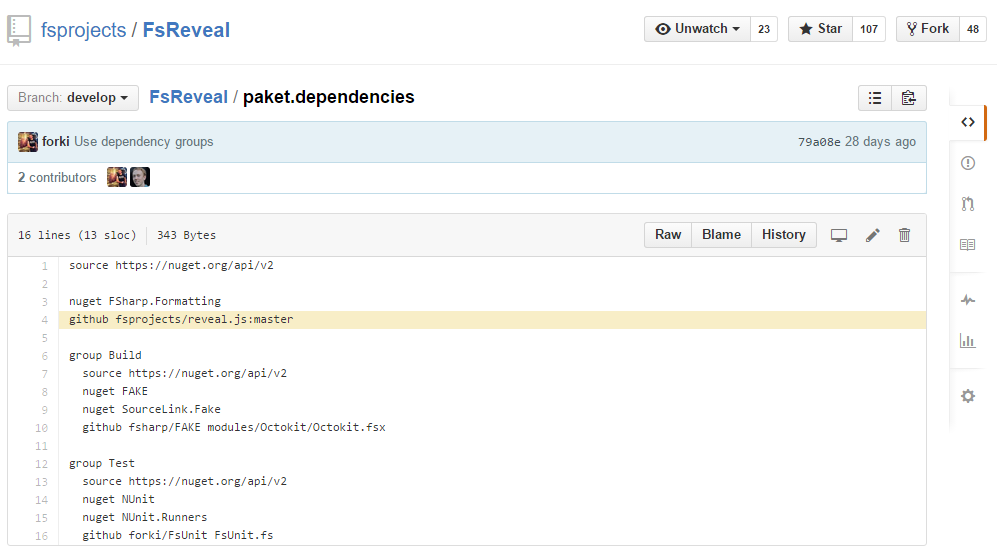
FsReveal
“FsReveal allows you to write beautiful slides in Markdown and brings C# and F# to the reveal.js web presentation framework.” [project site]
FsReveal uses Paket’s GitHub file dependencies┬Āfeature to download reveal.js:
It also uses┬Āa FAKE build script which converts Markdown files to html slides (via FSharp.Formatting) and runs these slides in a suave.io web server. FAKE’s file system watcher + suave’s socket implementation even allows you to edit your slides with automatic preview:
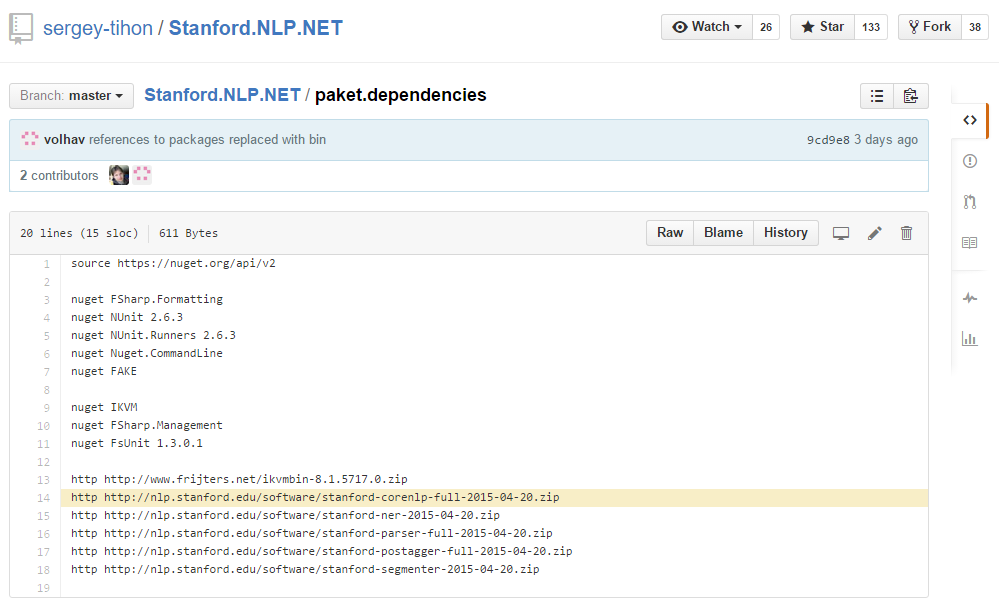
Stanford.NLP.NET
“Stanford.NLP for .NET is a port of Stanford NLP distributions to .NET.
This project contains build scripts that recompile Stanford NLP .jar packages to .NET assemblies using IKVM.NET, tests that help to be sure that recompiled packages are workable and Stanford.NLP for .NET documentation site that hosts samples for all packages. All recompiled packages are available on NuGet.” [project site]
This project downloads .jar packages via Paket’s HTTP dependencies┬Āfeature,┬Ārecompiles everything to .NET via IKVM.NET in a FAKE build script and republishes it on NuGet. Automatic Java to .NET compilation – how cool is that?
Paket.VisualStudio
“Manage your Paket dependencies from Visual Studio!” [project site]
Paket.VisualStudio is a VisualStudio addin that you can download from Microsoft’s VisualStudio gallery. Unfortunately even in 2015 Microsoft doesn’t provide an API for automating the upload to its gallery. Therefore Paket.VisualStudio┬Āuses Paket’s NuGet dependencies┬Āfeature to download canopy and Selenium:
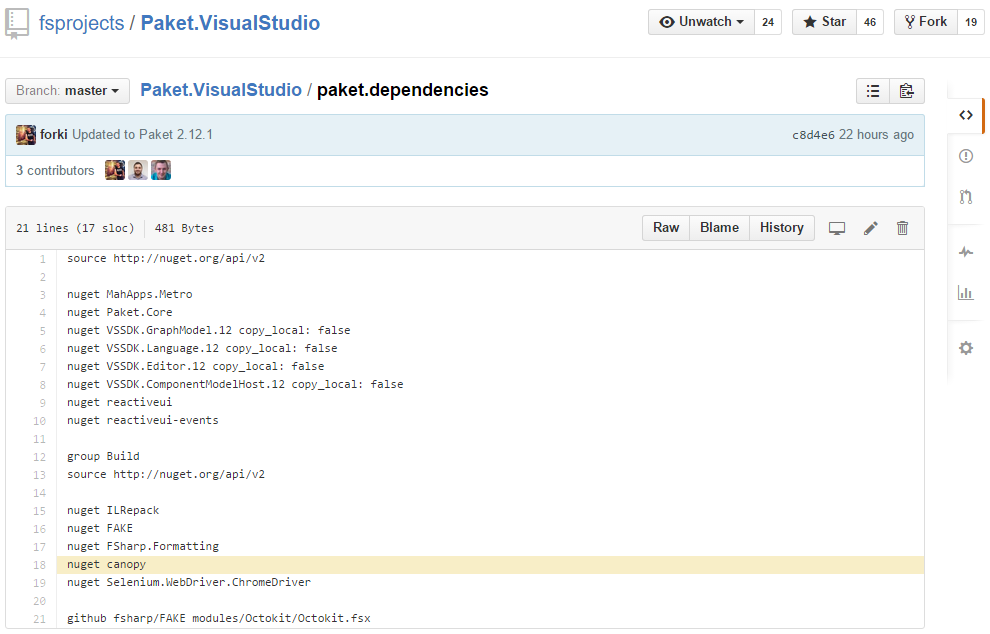
It then uses canopy + Selenium in a FAKE script to upload the addin via browser automation:

Ionide-F#
“It’s part of Ionide plugin suite. F# IDE-like possibilities in Atom editor” [project site]
Ionide is an Atom plugin written in F#. It’s using Paket and FAKE to automate the build and release process.
First it uses FunScript to transpile F# to Javascript and then automates npm┬Āto resolve Javascript dependencies and apm to upload the plugin to the Atom gallery.
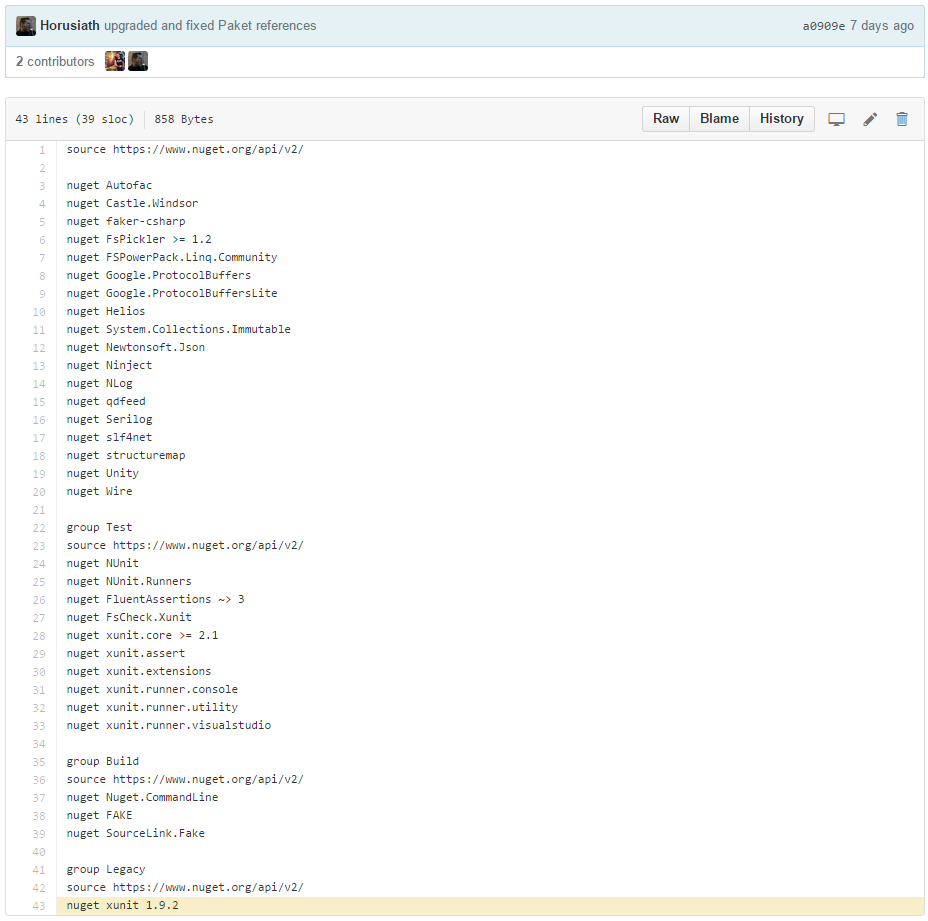
Akka.Net
“Akka.NET is a community-driven port of the popular Java/Scala framework Akka to .NET.” [project site]
Akka.Net is a big (mainly C#) open source project that uses FAKE and Paket. One interesting observation is that it needs to create┬Ādifferent xUnit addins and therefore uses Paket’s groups feature to maintain the xUnit versions.
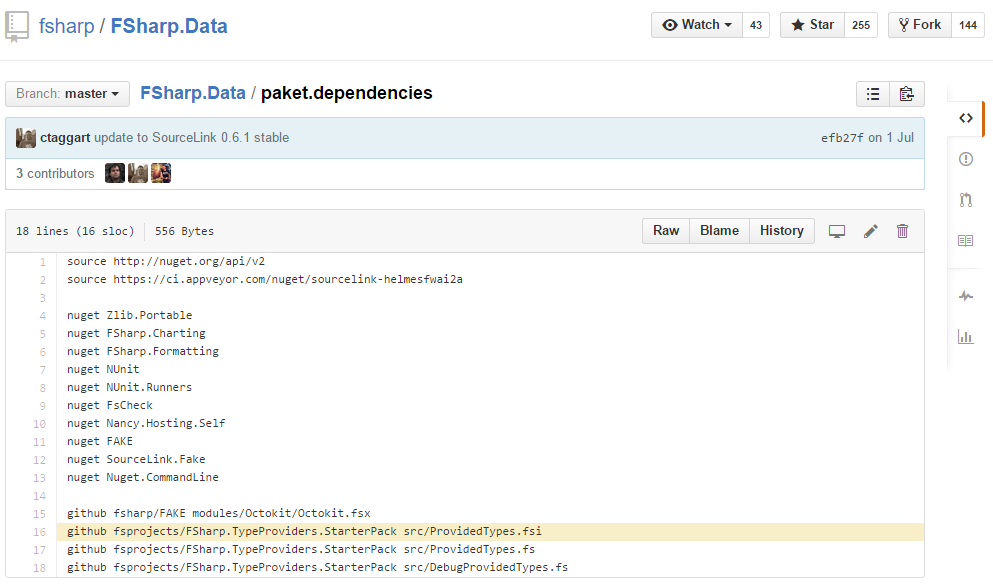
FSharp.Data
“The F# Data library┬Āimplements everything you need to access data in your F# applications and scripts. It implements F# type providers for working with structured file formats (CSV, HTML, JSON and XML) and for accessing the WorldBank data. It also includes helpers for parsing CSV, HTML and JSON files and for sending HTTP requests.” [project site]
One of the many interesting things in FSharp.Data’s build is that it uses Paket to retrieve the┬ĀFSharp.TypeProviders.StarterPack. These files need to be┬Āincluded in any F# type provider project and Paket allows you to manage this easily.
Tags:
F#,
F-sharp Make
Saturday, 5. July 2014
Jul 05
Recently Microsoft released all their major programming languages as open source and even started to accept pull requests. I┬Ādidn’t think┬Āthis would ever be possible at Microsoft, but they┬Āopened up and people like me started to contribute:
Personally I sent 29 (mostly small) pull requests to the Visual F# project. 5 pull requests┬Āalready got accepted┬Āand 15 are still under evaluation. ┬ĀIn principle the┬Ādevelopment process seems to be working very well. Especially in the Visual F# project Don Syme and the Visual F# team are doing an excellent job to encourage the community. They are marking user voice issues as “approved in principle”┬Āand even provide detailed documents for implementation tasks (See CoreLibraryFunctions). This makes it very easy to get started and to hack a bit on the F# compiler. A big thanks to you guys.
A very important part of the open source is the review process. The F# community is awesome in this regards. On issues like a new “compareWith” function I got comments with remarks about coding style, test cases, documentation and lots of new ideas about possible performance improvements. It’s really exciting to be part of such an active and welcoming community. There is only one “but” and this “but” is the choice of the development platform. I really think CodePlex┬Āis hindering these projects to become even more successful. In this post I want to show some of my experiences with Codeplex. Remember I already sent 29 pull requests so I think it’s fair to say I tried!
Overall usability
The first impression on the Codeplex site is that every click feels so frustrating slow. Waiting 4s and more for a site to load doesn’t exactly feel like 2014.
If you want to comment on something then there is an “interesting” distinction between issues and pull requests. On issues┬Āyou get a preview box and some buttons to make formatting easier, but you can’t edit your comments later:

On pull request you can edit your comments later but your don’t have the formatting buttons:

E-Mail notifications
Like most online portals you can enable E-Mail notifications on Codeplex. Unfortunately it doesn’t really work. I tried to set all notification sliders I found to the max. and still don’t get notifcations if someone sends a new pull request to the Visual F# projects. Instead I’m getting annoying E-Mail notifications on my own activities:

Things like this make you wonder if they actually dogfood their own stuff.
Code reviews on pull requests
As described above good code reviews are a very important part of any software development project, for open source programming language projects even more so. Unfortunately Codeplex has a really bad code review tool. I mean it is possible to comment on diffs:

But if you update the pull request with a fix then the comment is displayed on the new fixed code and makes no sense any more:

The whole code review is broken when you add commits to a pull request and it get’s even messier when you rebase your pull request on the current master. Rebasing pull requests is a very common operation in open source projects since it allows to move the merge effort from the project maintainer to the contributor. But unfortunately┬ĀCodeplex gets confused by the rebase and now shows a wrong diff:

A code platform shows a wrong diff – yep I couldn’t believe it myself so I tried again. #7040, #7045,┬Ā#7060, always the same.
Finding the needle in the hashstack
A couple of days ago I wanted to tweet a link to a cool performance trick and knew it was the last commit on a pull request. Now try to find the url:

Yes that’s right – the commits are ordered in alphabetical order BY HASH┬Āor as I call it in “least useful order”.
Reporting Codeplex issues
Of course you may ask: “Steffen why didn’t you report these issues to the Codeplex team?” and that’s a valid question.┬ĀActually I went to codeplex.codeplex.com,┬Āwhich I believe is the home of the Codeplex project, and looked at their┬Āissue list. This is what I got:

Not a single issue on the first page is related to Codeplex and it seems they don’t even care to close this spam. So why should I care to log issues there?
What now?
It’s more than┬Āobvious – use the “move source code to github” strategy and people already created an issue on the TypeScript project. Unfortunately it got closed:

After reading this┬ĀI really doubt it was the decision of the teams to use Codeplex. Fortunately the ASP.NET team seems to be an exception to this. Somehow they managed to move to github.com/aspnet.
There are also other ways. Microsoft could really invest in Codeplex and make it a usable platform. But I don’t see this happing, because it will cost A LOT of money. Even if they would open source Codeplex I don’t see a community which is willing to improve this site.
So I appeal to the people in charge at Microsoft please answer the following questions:
- What are the┬Āreasons for putting the Visual F# project┬Āon Codeplex, especially when the majority of the existing F# projects and community┬Āalready operate on Github?
- Do you think it’s more important to support Codeplex or to grow a community around the programming language projects?
- If the F# community voted for the project to be moved, would you consider moving it?
- If you insist on Codeplex how and when do you plan to fix these usability issues?
So please let your OSS┬Āteams and their community┬Āpick the open source platform they want!
Wednesday, 15. January 2014
Jan 15
As part of a longer process of making FSharpx┬Ābetter maintainable I created a new project called┬ĀFSharp.Configuration.┬ĀIt contains type providers for the configuration of .NET projects:

Additonal information:
Please tell me what you think.
Tuesday, 14. January 2014
Jan 14
I’m happy to annouce the new release of the┬ĀFSharpx.Collections package on nuget.
Most important changes:
Please tell me if it works for you.
Tuesday, 16. April 2013
Apr 16
I love to work on open source projects, but from time to time I have my doubts. My friend Daniel Nauck created a wonderful open source licensing project (see my blog post) and now we had to see this:

I am not a lawyer and rebranding a tool might be permitted by the MIT license, but seriously what are they thinking?
They even removed license information from the source files.
// The above copyright notice and this permission notice shall be
// included in all copies or substantial portions of the Software.
ItŌĆÖs really ironic to violate the license of a licensing tool, but please donŌĆÖt be that guy!
Tags:
C-Sharp,
portable.licensing